
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- speech reconstruction
- 신경과학
- spoken speech
- 잠재변수
- matlab
- neural representation learning
- latent variable
- 뇌과학
- AI
- brain-to-speech
- 발화의도
- csp알고리즘
- 블록체인
- 기준음성
- BCI
- neurotalk
- 뇌와 세계
- csp 알고리즘
- HPC
- 헬싱키 선언
- Distributed Representation
- 분산표현
- 미겔
- gt voice
- 책
- 의료윤리
- 표현학습
- AI윤리
- common spatial pattern
- imagined speech
- Today
- Total
o0y0o
[논문번역] Towards Voice Reconstruction from EEG during Imagined Speech (2/2) 본문
[논문번역] Towards Voice Reconstruction from EEG during Imagined Speech (2/2)
_\oyo/_ 2024. 9. 19. 21:34저번 글에 이어서 번역을 마무리해 보았습니다. 오류 지적은 언제든 감사히 받고 있습니다.
논문에 제시된 대로 따라서 모델 및 코드를 분석해 보고, 저의 개인 탐구 프로젝트에 적용해 보면 좋을 것 같습니다.
■ Experimental Setup
▷ Dataset
Participants
연구에는 여섯 명의 참가자가 자발적으로 참여하였습니다. 여기서 자발적이란, 참가자들이 연구 목적과 절차에 대해 충분히 이해하고 동의한 상태에서 참여했다는 것을 의미합니다.
이 연구는 헬싱키 선언에 따라 진행되었으며, 한국대학교 기관생명윤리위원회(Korea University Institutional Review Board [KUIRB-2019-0143-01])의 승인을 받았습니다.
모든 대상자로부터 정보에 입각한 동의를 받았습니다.
Paradigms
spoken speech 세션의 경우, 참가자들은 무작위로 주어진 13개의 구절을 자연스럽게 발음하도록 지시받았으며, 열두 단어/구절(ambulance, clock, hello, help me, light, pain, stop, thank you, toilet, TV, water, and yes)과 침묵 기간이 청각적으로 제시되었습니다.
음성 데이터는 시각적이나 청각적인 방해를 피하기 위해 리드미컬하게 녹음되었습니다. 리드미컬하게 녹음되었다는 의미는, 음성의 일정한 리듬과 패턴을 유지하며 녹음하였다는 의미입니다. 음성의 톤, 속도, 길이 등을 균일하게 유지함으로써 더 분석하기 쉬운 형태로 처리될 수 있습니다.
imagined speech 데이터는 선행연구(Lee, Lee, and Lee 2020)를 따라 spoken speech와 정확히 동일한 방식으로 수집되었습니다.
각 참가자는 각 클래스별로 spoken speech와 imagined speech를 100 Trial 수행하였습니다. 따라서 각 참가자는 spoken과 imagined speech paradigms에 대해 1300 Trial을 수행하였습니다.
Recording
이 연구에서 사용된 데이터셋은 spoken/imagined speech의 두피 EEG 녹음과 spoken speech의 음성 녹음으로 구성되어 있습니다.
실험 동안, EEG 신호는 Brain Vision/Recorder(BrainProduct GmbH, Germany)를 통해 2500Hz의 sampling rate로 녹음되었고, spoken speech의 해당 오디오는 동시에 8000Hz의 sampling rate로 녹음되었습니다.
brain signals는 국제 10-10 system을 따르는 64채널 EEG cap과 active Ag/AgCl electrode 배치를 통해 녹음되었습니다.
▷ Pre-processing
EEG signals은 각 Trial 마다 2초 간격으로 추출되었습니다. 1 Trial이 2초라는 걸 의미합니다.
데이터는 주로 음성 관련 정보를 포함하는 것으로 알려진 고주파 대역(30–120 Hz)에서 5차 Butterworth 대역 통과 필터로 필터링되었습니다(Lachaux et al. 2012; Lee, Lee, and Lee 2020).
Notch 필터는 60 Hz의 전원선 노이즈와 120 Hz의 고조파를 제거하는 데 사용되었습니다.
spoken speech의 electrooculography (EOG)와 electromyography (EMG)는 EOG와 EMG를 참조하여 blind source separation을 사용하여 제거되었습니다(Gómez-Herrero et al. 2006).
Baseline은 각 시험 전 500 ms의 평균 값을 빼서 보정되었습니다.
전처리 과정은 Python과 Matlab을 사용하여 OpenBMI Toolbox(Lee et al. 2019), BBCI Toolbox(Krepki et al. 2007), 및 EEGLAB(Delorme and Makeig 2004)을 사용하여 수행되었습니다.
음성 데이터의 경우, 음성 신호를 22050 Hz로 리샘플링하고 noisereduce 라이브러리(Sainburg 2019; Sainburg, Thielk, and Gentner 2020)를 사용하여 노이즈를 줄였습니다.
▷ Dataset Composition and Training Procedure
Imagined speech는 정의상 모델을 훈련시킬 GT voice가 없습니다. 그러나 spoken speech는 실제 음성 출력이 수반므로, 각 spoken speech 오디오와 EEG data가 완벽하게 시간적으로 정렬된 쌍으로 수집되었습니다.
imagined speech와 spoken speech의 실험 설계가 완전히 동일했기에, 각 참가자의 동일한 문장에 대한 spoken speech늬 음성 녹음이 imagined speech를 평가하기 위한 GT voice로 사용되었습니다.
또한, imagined speech brain speech에 대한 GT voice가 없기에, spoken voice EEG과 spoken voice 오디오로 훈련된 모델을 imagined speech EEG에 전이학습하였습니다.
데이터셋은 random seed를 사용한 랜덤 선택에 따라 5-fold로 training, validation, test 데이터셋으로 나누어졌습니다.
보이지 않는 단어 'stop'은 데이터셋에서 분리되어 training set에 포함되지 않았습니다. 이 단어는 보이지 않는 경우를 테스트하기 위해 선택되었으며, 'stop'을 구성하는 모든 phoneme은 training에 사용된 나머지 11개의 단어로 커버되었습니다.
이로써 stop이라는, 학습되지 않은 단어가 모델에 의해 인식될 수 있는지 테스트할 수 있습니다.
즉, 우리는 11개의 단어/구절과 침묵 단계를 training 데이터셋으로 훈련시켰고, 보이지 않는 단어를 포함한 12개의 단어/구절과 침묵 구간을 validation과 test 데이터셋에서 검증했습니다.
Generator와 discriminator는 각 Trial의 GT voice와 함께 spoken EEG 데이터를 사용하여 먼저 훈련되었습니다. 이 단계에서 모델은 실제 음성과 뇌파 데이터가 어떻게 연관되는지 학습합니다.
imagined speech는 각 Trial의 voice가 없기 때문에, spoken speech 동안의 voice가 ground truth로 사용되었습니다.
spoken speech의 EEG와 voice 사이의 시간 지점을 일치시키기 위해, EEG의 합성 mel-spectrogram과 voice의 mel-spectrogram에 DTW가 적용되었습니다.
또한, generator와 discriminator는 spoken EEG의 훈련된 모델에서 전이 학습을 수행하여 imagined EEG와 spoen speech 동안의 voice 사이에 자연스럽게 연결되었습니다. 이 단계에서 모델은 spoken speech와 imagined 이미지 사이의 관계를 모델링합니다.
▷ Model Implementation Details
Generator는 커널 크기가 3, 7, 11이고 각각의 dilation은 1, 3, 5이며, upsampling rate는 3, 2, 2로 두 배의 upsample 커널 크기를 가진 세 개의 residual block을 가지고 있습니다. Residual block은 신경망의 성능을 향상시키는 구조로, 각 block은 다른 특성을 추출할 수 있도록 다양한 크기의 커널과 dilation을 사용합니다. [출처]
초기 채널의 수는 1024였고, directional GRU의 차원은 초기 채널의 절반입니다.
Discriminator는 generator와 동일한 residual block을 가졌지만, downsampling rate는 3, 3, 3이고 커널 크기는 두 배였습니다. Downsampling은 데이터의 차원을 줄여 처리 속도를 빠르게 하고 과적합을 방지하는 데 도움을 줍니다. Discriminator의 역할은 생성된 데이터가 진짜 데이터와 얼마나 가까운지를 판별하는 것입니다.
최종 채널의 수는 64였고, directional GRU의 차원은 최종 채널의 절반입니다. 최종 채널 수의 감소는 모델의 출력 단계에서 필요한 처리량을 줄이고, 계산 복잡성을 낮추는 역할을 합니다. 여기서도 GRU는 주어진 차원을 기반으로 데이터의 시퀀스 특성을 처리합니다.
Mel-spectrogram은 22050 Hz의 sampling rate으로 관리되었고, STFT와 mel 함수는 nFFT 1024, window 1024, hop size 256, 그리고 80 bands의 mel-spectrograms으로 수행되었습니다.
초기 훈련은 초기 학습률 10^-4로 수행되었고, fine-tuning은 최대 epoch 500 및 batch size 10에서 학습률 10^-5로 수행되었습니다.
모델은 NVIDIA GeForce RTX 3090 GPU에서 훈련되었습니다.
AdamW optimizer (Loshchilov and Hutter 2017)를 사용하였고, β1=0.8, β2=0.99, 그리고 weight decay λ=0.01의 파라미터가 매 epoch마다 0.999 factor로 스케줄되었습니다.
소스 코드와 샘플 데이터는 Github에서 공개되었습니다: https://github.com/youngeun1209/NeuroTalk
▷ Evaluation Metrics
평가 지표로는 root mean square error (RMSE), character error rate (CER), 그리고 주관적인 mean opinion score (MOS) 테스트를 사용했습니다. RMSE는 예측 값과 실제 값의 차이를 수치화하여 모델의 정확도를 측정하고, CER은 문자 인식의 오류율을 평가하여 ASR의 효율을 측정하며, MOS는 인간 평가자의 주관적 평가를 통해 음성의 질을 평가합니다.
Generator의 정확한 reconstruct 성능을 평가하기 위해, 목표와 reconstruct 된 mel-spectrogram 사이의 RMSE를 계산했습니다
명확성을 정량적으로 평가하기 위해, ASR 모델을 거친 후 CER을 실시했습니다. CER은 생성된 텍스트의 문자 오류율을 측정하여, ASR 모델이 얼마나 정확하게 음성에서 텍스트를 인식하는지 평가합니다.
주관적 평가를 위해, reconstruct 된 음성의 품질을 평가하는 MOS 테스트가 실시되었습니다. MOS 테스트는 사람들이 직접 듣고 평가하는 방식으로, 음성의 자연스러움, 명료성 등을 종합적으로 평가합니다.
테스트 데이터셋에서 무작위로 125개의 음성 샘플을 선택했습니다. 샘플들은 0.5점 단위로 1-5의 척도에서 20명 이상의 평가자에 의해 평가되었습니다.
EEG 데이터셋과 GT, 그리고 mel-spectrogram, waveform, character 형태로 변환된 GT를 비교했습니다. 다양한 형식으로 변환된 데이터와 ground truth(GT) 데이터를 비교하여 모델의 성능을 다각도로 평가하는 과정으로 보입니다.
또한, NeuroTalk의 확장성을 입증하기 위해, 훈련된 단어 클래스에 포함된 음소로 구성된 보이지 않는 단어의 생성 성능을 평가했습니다. 모델이 학습되지 않은 새로운 데이터에 대해 어떻게 반응하는지를 테스트합니다. 이로써 모델이 훈련 데이터 이상의 범위에서 작동할 수 있음을 보여주며, 실제 상황에서 유용하게 사용될 수 있음을 확인합니다.
■ Results and Discussion

Mel-spectrogram과 원본 음성, EEG에서 reconstruct 된 음성의 오디오 wave입니다. reconstruct의 예로는 ‘Hello’, ‘Water’, ‘Help me’가 있습니다.
spoken and imagined EEG의 침묵 기간도 성공적으로 디코딩되었습니다. 보이지 않는 경우들도 성능이 떨어지지만 reconstruct되었습니다.
▷ Voice Reconstruction from EEG
음성 샘플은 데모 페이지에 포함되어 있습니다: https://neurotalk.github.io/demo/neurotalk.html.
Figure 3은 원본 음성, spoken speech EEG에서 reconstruct 된 음성, 그리고 imagined speech EEG에서 reconstruct 된 음성의 mel-spectrogram과 오디오 wave를 보여줍니다.
그림에서 보이듯이, 성공적으로 reconstruct 된 경우에는 mel-spectrogram과 오디오 파형의 유사한 패턴을 보여줍니다.

Table 1은 뇌 신호에서 reconstruct된 음성의 평가 결과를 GT와 비교하여 보여줍니다.
구체적으로 Table 1의 값들을 뜯어보자면, 우선 이 Table은 다양한 모델들을 통해 reconstruct 된 음성의 주관적 및 정량적 평가 결과를 담고 있습니다. 평가 지표로는 root mean square error (RMSE), character error rate (CER), mean opinion score (MOS)가 사용되었습니다.
Ground Truth (GT)와 변환된 음성(Mel → ASR) 모델은 CER과 MOS로만 평가되었으며, 기준 데이터이므로 RMSE 계산 대상이 아닙니다. GT의 경우 CER은 18.35%, MOS는 3.67로 나타나, 비교적 낮은 문자 오류율과 높은 주관적 만족도를 보여줍니다. 변환된 음성은 CER이 다소 증가한 23.35%를 보였으며, MOS는 GT와 유사한 3.68을 기록했습니다.
Spoken EEG와 Imagined EEG 모델은 각각의 reconstruct 된 음성의 RMSE, CER, 그리고 MOS를 통해 평가되었습니다. Spoken EEG는 RMSE가 0.166으로 가장 낮으며, CER는 40.21%, MOS는 3.34로 비교적 높은 주관적 만족도를 나타냈습니다. 반면, Imagined EEG는 모든 지표에서 상대적으로 열등한 성능을 보였습니다. RMSE는 0.175, CER는 68.26%로 매우 높으며, MOS는 2.78로 가장 낮습니다.
Unseen Spoken EEG와 Unseen Imagined EEG는 학습되지 않은 데이터를 사용하여 모델의 일반화 능력을 평가합니다. Unseen Spoken EEG는 RMSE 0.185, CER 78.89%, MOS 2.87로 나타났으며, Unseen Imagined EEG는 RMSE가 0.187, CER가 83.06%로 가장 높고, MOS는 2.57로 가장 낮게 평가되었습니다.
RMSE와 CER의 객관적 측정은 imagined speech EEG의 경우에 spoken speech EEG에 비해 열등한 성능을 보여주었습니다.
spoken speech 경우의 MOS는 GT와 큰 차이 없이 높았는데, 이는 모델이 spoken EEG에서 자연스러운 음성을 생성할 수 있음을 의미합니다.
흥미롭게도, 보이지 않는 spoken EEG는 객관적 평가인 RMSE와 CER에서 열등했음에도 불구하고 imagined EEG보다 높은 MOS를 보여주었는데, 이는 동시에 음성을 생성하는 spoken EEG를 reconstruct하면 자연스러운 음성을 생성할 수 있음을 시사합니다. reconstruct 된 음성의 주관적 성능이 객관적 오류율과 항상 일치하지 않을 수 있음을 보여줍니다. 보이지 않는 spoken EEG 샘플들이 더 높은 MOS를 얻었다는 것은, 이 샘플들이 실제 사용자에게 더 자연스럽게 들릴 수 있음을 의미합니다. 심지어 기술적 오류가 더 많음에도 불구하고 말입니다. 이는 실제 음성 발화가 이루어지는 동안 brain signals를 동시에 측정하여 음성을 처리하는 spoken EEG 데이터의 잠재적 우수성을 강조하는 듯 합니다.
Figure 3에서 보여지듯이, 침묵 단계의 테스트 샘플은 활성화 없이 성공적으로 재구성되었습니다. spoken 및 imagined EEG의 침묵 사례는 imagined speech의 한 사례를 제외하고 성공적으로 디코드되었습니다.
이 결과에 따르면, 우리의 NeuroTalk 모델이 침묵 기간을 정확하게 학습하고 spoken speech 및 imagined speech EEG에서 정확한 시작을 감지할 수 있음을 추론할 수 있습니다.
비록 imagined speech가 기준 음성이 없지만, 제안된 NeuroTalk 프레임워크는 spoken speech 기반 모델을 imagined speech EEG에 효과적으로 적응시켜 뇌 신호에서 사용자의 의도를 디코드하고 음성을 생성할 수 있음을 보여줍니다.
Figure 4에서 나타나듯이, imagined speech에서 일부 실패 사례가 있었습니다.
성공과 실패 사례 간의 주요 차이점은 침묵 기간을 감지하는지 여부였습니다.
Figure 4에서 보이는 실패 사례 중 하나는 CER이 50%로, 'thank'와 'you' 사이에 거의 침묵 기간이 없습니다. 또한, CER이 100%인 실패 사례는 기준 진리에서 어떤 문자도 대표할 수 없는 몇 마디 단어만을 생성했습니다.
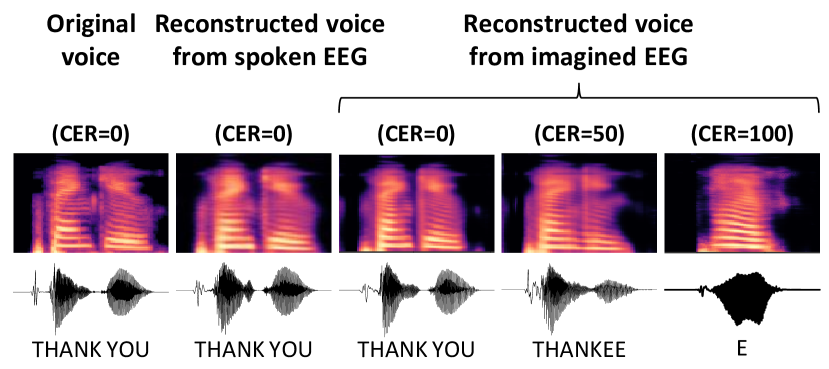
성공 사례와 실패 사례. 원본 음성과 reconstructed 음성에 대한 Mel-spectrogram과 waveform이 표시되었습니다.
▷ Ablation Study
Ablation Study는 모델의 성능에 가장 큰 영향을 미치는 요소를 찾기 위해 모델의 구성요소 및 feature들을 단계적으로 제거 하거나 변경해가며 성능의 변화를 관찰하는 방법입니다. [출처]
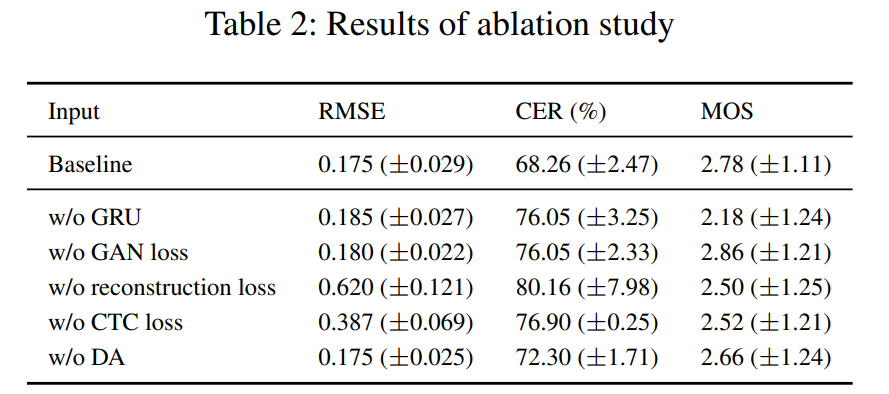
Ablation Study 결과는 Table 2에 나타나 있습니다. 모델에 모듈을 추가하는 것을 명확히 하기 위해 generator와 discriminator에서 GRU의 Ablation Study를 수행했으며, 각 손실이 generator의 성능에 미치는 영향을 검증하기 위해 GAN loss, reconstruction loss, 그리고 CTC loss를 조사했습니다.
객관적 평가에서는 reconstruction loss 없이 성능이 가장 나쁘며, 그 다음이 CTC loss로, reconstruction loss 다음으로 CTC loss가 프레임워크에 가장 큰 영향을 미칩니다.
또한 모든 사례의 결과가 기준선보다 훨씬 나빴는데, 이는 모든 사례가 각각의 역할을 수행하고 있음을 나타내며, 특히 reconstruction loss이 훈련에 가장 큰 영향을 미칩니다
주관적 평가에서는 자연스러움이 어느 정도 다른 경향을 보이며, GRU가 없는 결과가 자연스러움이 떨어져 가장 나쁜 결과를 보여줍니다. 이는 순차적 특징이 자연스러운 음성 합성에 중요하다는 것을 보여줍니다. GRU가 없을 때 음성이 부자연스러워지는 것은 GRU가 시퀀스 데이터를 효과적으로 처리하여 더 자연스러운 음성 생성에 기여하기 때문입니다.
▷ Voice Reconstruction of Unseen Words
보이지 않는 훈련되지 않은 단어는 EEG에서 재구성될 수 있었으며, chance level보다 훨씬 낮은 CER을 보였고, MOS가 3 이상으로 상당히 높은 품질의 오디오를 생성했습니다. MOS는 1~5의 척도로 평가됩니다.
훈련된 단어와 비교했을 때, 보이지 않는 경우에 spoken 및 imagined EEG의 CER 차이는 상대적으로 작았습니다.
이 결과들은 훈련된 단어에 대한 spoken EEG의 견고한 성능이 움직임 아티팩트에 의해 훈련된 클래스에 과적합될 수 있음을 시사하며, imagined speech는 훈련된 단어의 음소를 포착하여 보이지 않는 단어를 생성하는 데 상대적으로 효과적일 수 있음을 보여줍니다.
아직 더 개션할 여지가 있음에도 불구하고, 우리의 결과는 NeuroTalk 모델이 여러 단어 수준 데이터셋에 대한 훈련을 통해 디코딩 가능한 단어나 문장의 자유도를 확장할 수 있는 잠재력이 있음을 보여줍니다.
우리는 CTC loss는 인간의 의도가 포함된 brain signals에서도 단어의 특정이나 phoneme 정보를 학습할 수 있을 것으로 기대합니다.
모델을 제한된 단어/구절로 훈련했기에 단순히 EEG를 train class 중 하나로 분류하고 있을 수 있습니다. 그러나 이 모델은 train set에서 보이지 않는 단어를 생성할 수 있는 잠재력을 보여주었으며, 이는 모델이 일반화되고 학습 세트 외부의 클래스로 확장될 가능성을 나타냅니다.
▷ Domain Adaptation
DA는 CSP subspaces를 공유하고, spoken speech-based trained model을 imagined speech EEG로 전이시키는 방식으로 수행되었습니다.
Table 2에서 보여지듯, DA를 적용한 결과는 기준선에 비해 우수한 성능을 보였습니다.
이 결과는 spoken speech EEG가 imagined speech EEG 훈련에 유용함을 의미하며, imagined speech와 spoken speech의 신경적 기반에는 embedding vector로 표현될 수 있는 공통적인 특징들이 존재함을 시사합니다.
말 생성과 발음은 주로 하위 전두엽 회로인 Broca’s area와 관련이 있습니다. Angular gyrus는 청각, 운동, 감각 및 시각 피질에서 언어 관련 활동을 연결하는 역할을 하므로, 말 과정에서는 왼쪽 측두엽 뿐만 아니라 전체 뇌가 기능할 수 있습니다 (Watanabe et al. 2020).
전체 채널 EEG에서 생성된 우리의 embedding vector는 발음 정보와 발화 의도를 모두 포함할 가능성이 있습니다.
따라서, 우리는 spoken speech EEG와 imagined speech EEG의 유사성을 참조하여 말과 관련된 정보를 추출함으로써 음성을 생성할 수 있는 잠재력을 보여줍니다.
▷ Leave-one-out Scenario
우리는 상상된 말만을 사용할 수 있는 locked-in 환자들에게 NeuroTalk 시스템을 적용하기 위해, 보이지 않는 새로운 사람의 데이터에 적용할 수 있도록 leave-one-out (LOO) 접근 방식의 추가 실험을 수행했습니다.
이 모델은 한 명의 참가자를 제외한 모든 참가자의 spoken EEG로 훈련되었으며, 제외된 참가자의 imagined EEG로 미세 조정되었습니다.
그 결과, 기준선보다 떨어지지만 DA가 없는 것보다는 나은 비슷한 성능을 얻었습니다.
LOO 접근 방식을 기반으로, 우리는 framework를 완전히 새로운 사람으로 확장할 수 있는 잠재력을 발견했으며, 이는 자신의 목소리를 잃은 사람들을 더욱 도울 수 있습니다.
■ Conclusion
우리는 imagined speech 동안 EEG로부터 사용자의 목소리를 재구성하는 NeuroTalk을 제시했습니다.
DA 접근 방식은 spoken speech EEG의 훈련된 모델을 사용하여 imagined speech EEG의 모델을 훈련시키고 feature embedding을 공유함으로써 수행되었습니다.
우리의 결과는 단어 수준에서 non-invasive brain signals의 imagined speech로부터 음성을 재구성할 수 있는 가능성을 보여줍니다.
또한, 성능이 높지 않음에도 몇 개의 문자로 구성된 보이지 않는 단어를 생성할 수 있으며, 이는 우리가 향후 더 큰 데이터셋과 문장 수준의 음성 합성으로 연구를 확장할 수 있음을 의미합니다.
우리는 이 연구가 인간의 의사소통 수단을 확장하고 환자나 장애인이 의사소통의 자유를 얻는 데 도움이 되기를 바랍니다. 우리는 아무 말도 하지 않고 의사소통할 수 있는 세상을 기대합니다.
■ Acknowledgement
이 연구는 Korea government(MSIT)에서 지원하는 Institute for Information & Communications Technology Planning & Evaluation (IITP) 지원을 받았습니다.
(과제번호: 2021-0-02068, Artificial Intelligence Innovation Hub; 과제번호: 2017-0-00451, Development of BCI based Brain and Cognitive Computing Technology for Recognizing User’s Intentions using Deep Learning; 과제번호: 2019-0-00079, Artificial Intelligence Graduate School Program(Korea University))
■ References
Akbari, H.; Khalighinejad, B.; Herrero, J. L.; Mehta, A. D.; and Mesgarani, N. 2019. Towards reconstructing intelligible speech from the human auditory cortex. Scientific Reports, 9(1): 1–12. Angrick, M.; Herff, C.; Mugler, E.; Tate, M. C.; Slutzky, M. W.; Krusienski, D. J.; and Schultz, T. 2019. Speech synthesis from ECoG using densely connected 3D convolutional neural networks. Journal of Neural Engineering, 16(3): 036019. Angrick, M.; Ottenhoff, M.; Diener, L.; Ivucic, D.; Ivucic, G.; Goulis, S.; Colon, A. J.; Wagner, L.; Krusienski, D. J.; Kubben, P. L.; et al. 2022. Towards closed-Loop speech synthesis from stereotactic EEG: A unit delection approach. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1296– 1300. IEEE. Angrick, M.; Ottenhoff, M.; Goulis, S.; Colon, A. J.; Wagner, L.; Krusienski, D. J.; Kubben, P. L.; Schultz, T.; and Herff, C. 2021a. Speech synthesis from stereotactic EEG using an electrode shaft dependent multi-input convolutional neural network approach. In 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), 6045–6048. IEEE. Angrick, M.; Ottenhoff, M. C.; Diener, L.; Ivucic, D.; Ivucic, G.; Goulis, S.; Saal, J.; Colon, A. J.; Wagner, L.; Krusienski, D. J.; et al. 2021b. Real-time synthesis of imagined speech processes from minimally invasive recordings of neural activity. Communications Biology, 4(1): 1–10. Anumanchipalli, G. K.; Chartier, J.; and Chang, E. F. 2019. Speech synthesis from neural decoding of spoken sentences. Nature, 568(7753): 493–498. Baevski, A.; Zhou, Y.; Mohamed, A.; and Auli, M. 2020. wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in Neural Information Processing Systems, 33: 12449–12460. Chaudhary, U.; Birbaumer, N.; and Ramos-Murguialday, A. 2016. Brain–computer interfaces for communication and rehabilitation. Nature Reviews Neurology, 12(9): 513–525. Cho, K.; Van Merrienboer, B.; Gulcehre, C.; Bahdanau, ¨ D.; Bougares, F.; Schwenk, H.; and Bengio, Y. 2014. Learning phrase representations using RNN encoderdecoder for statistical machine translation. arXiv preprint arXiv:1406.1078. Cooney, C.; Folli, R.; and Coyle, D. 2018. Neurolinguistics research advancing development of a direct-speech braincomputer interface. IScience, 8: 103–125. Delorme, A.; and Makeig, S. 2004. EEGLAB: an open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. Journal of Neuroscience Methods, 134(1): 9–21. Devlaminck, D.; Wyns, B.; Grosse-Wentrup, M.; Otte, G.; and Santens, P. 2011. Multisubject learning for common spatial patterns in motor-imagery BCI. Computational Intelligence and Neuroscience, 2011. Gaddy, D.; and Klein, D. 2020. Digital voicing of silent speech. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 5521– 5530. Gaddy, D.; and Klein, D. 2021. An improved model for voicing silent speech. arXiv preprint arXiv:2106.01933. Goldstein, A.; Zada, Z.; Buchnik, E.; Schain, M.; Price, A.; Aubrey, B.; Nastase, S. A.; Feder, A.; Emanuel, D.; Cohen, A.; et al. 2022. Shared computational principles for language processing in humans and deep language models. Nature neuroscience, 25(3): 369–380. Gomez-Herrero, G.; De Clercq, W.; Anwar, H.; Kara, O.; ´ Egiazarian, K.; Van Huffel, S.; and Van Paesschen, W. 2006. Automatic removal of ocular artifacts in the EEG without an EOG reference channel. In Proceedings of the 7th Nordic signal processing symposium-NORSIG 2006, 130– 133. IEEE. Gonzalez, J. A.; Cheah, L. A.; Gomez, A. M.; Green, P. D.; Gilbert, J. M.; Ell, S. R.; Moore, R. K.; and Holdsworth, E. 2017. Direct speech reconstruction from articulatory sensor data by machine learning. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 25(12): 2362–2374. Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; and Bengio, Y. 2014. Generative adversarial nets. Advances in neural information processing systems, 27. Graimann, B.; Allison, B.; and Pfurtscheller, G. 2009. Brain–computer interfaces: A gentle introduction. In BrainComputer Interfaces, 1–27. Springer. Graves, A.; Fernandez, S.; Gomez, F.; and Schmidhuber, J. ´ 2006. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd international conference on Machine learning, 369–376. Herff, C.; Diener, L.; Angrick, M.; Mugler, E.; Tate, M. C.; Goldrick, M. A.; Krusienski, D. J.; Slutzky, M. W.; and Schultz, T. 2019. Generating natural, intelligible speech from brain activity in motor, premotor, and inferior frontal cortices. Frontiers in Neuroscience, 13: 1267. Herff, C.; Krusienski, D. J.; and Kubben, P. 2020. The potential of stereotactic-EEG for brain-computer interfaces: current progress and future directions. Frontiers in Neuroscience, 14: 123. Hsu, W.-N.; Bolte, B.; Tsai, Y.-H. H.; Lakhotia, K.; Salakhutdinov, R.; and Mohamed, A. 2021. HuBERT: Selfsupervised speech representation learning by masked prediction of hidden units. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29: 3451–3460. Isola, P.; Zhu, J.-Y.; Zhou, T.; and Efros, A. A. 2017. Imageto-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1125–1134. Kong, J.; Kim, J.; and Bae, J. 2020. Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis. Advances in Neural Information Processing Systems, 33: 17022–17033. Krepki, R.; Blankertz, B.; Curio, G.; and Muller, K.-R. 2007. ¨ The Berlin Brain-Computer Interface (BBCI)–towards a new communication channel for online control in gaming applications. Multimedia Tools and Applications, 33(1): 73– 90. Krishna, G.; Tran, C.; Han, Y.; Carnahan, M.; and Tewfik, A. H. 2020. Speech synthesis using EEG. In ICASSP 2020- 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1235–1238. IEEE. Lachaux, J.-P.; Axmacher, N.; Mormann, F.; Halgren, E.; and Crone, N. E. 2012. High-frequency neural activity and human cognition: past, present and possible future of intracranial EEG research. Progress in Neurobiology, 98(3): 279–301. Lee, M.-H.; Kwon, O.-Y.; Kim, Y.-J.; Kim, H.-K.; Lee, Y.- E.; Williamson, J.; Fazli, S.; and Lee, S.-W. 2019. EEG dataset and OpenBMI toolbox for three BCI paradigms: an investigation into BCI illiteracy. GigaScience, 8(5): giz002. Lee, S.-H.; Lee, M.; and Lee, S.-W. 2019. EEG representations of spatial and temporal features in imagined speech and overt speech. In Asian Conference on Pattern Recognition, 387–400. Lee, S.-H.; Lee, M.; and Lee, S.-W. 2020. Neural decoding of imagined speech and visual imagery as intuitive paradigms for BCI communication. IEEE Transactions on Neural Systems and Rehabilitation Engineering. Lee, S.-H.; Lee, Y.-E.; and Lee, S.-W. 2022. Toward imagined speech based smart communication system: potential applications on metaverse conditions. In 2022 10th International Winter Conference on Brain-Computer Interface (BCI), 1–4. IEEE. Loshchilov, I.; and Hutter, F. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101. Makin, J. G.; Moses, D. A.; and Chang, E. F. 2020. Machine translation of cortical activity to text with an encoder– decoder framework. Nature neuroscience, 23(4): 575–582. Nguyen, C. H.; Karavas, G. K.; and Artemiadis, P. 2017. Inferring imagined speech using EEG signals: a new approach using Riemannian manifold features. Journal of neural engineering, 15(1): 016002. Proix, T.; Delgado Saa, J.; Christen, A.; Martin, S.; Pasley, B. N.; Knight, R. T.; Tian, X.; Poeppel, D.; Doyle, W. K.; Devinsky, O.; et al. 2022. Imagined speech can be decoded from low-and cross-frequency intracranial EEG features. Nature Communications, 13(1): 1–14. Saha, P.; Abdul-Mageed, M.; and Fels, S. 2019. SPEAK YOUR MIND! Towards imagined speech recognition with hierarchical deep learning. Proc. Interspeech 2019, 141– 145. Sainburg, T. 2019. timsainb/noisereduce: v1.0. Sainburg, T.; Thielk, M.; and Gentner, T. Q. 2020. Finding, visualizing, and quantifying latent structure across diverse animal vocal repertoires. PLoS Computational Biology, 16(10): e1008228. Schultz, T.; Wand, M.; Hueber, T.; Krusienski, D. J.; Herff, C.; and Brumberg, J. S. 2017. Biosignal-based spoken communication: A survey. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 25(12): 2257–2271. Si, X.; Li, S.; Xiang, S.; Yu, J.; and Ming, D. 2021. Imagined speech increases the hemodynamic response and functional connectivity of the dorsal motor cortex. Journal of Neural Engineering, 18(5): 056048. Wang, L.; Zhang, X.; Zhong, X.; and Zhang, Y. 2013. Analysis and classification of speech imagery EEG for BCI. Biomedical signal processing and control, 8(6): 901–908. Wang, Z.; and Ji, H. 2021. Open vocabulary Electroencephalography-To-Text decoding and zero-shot sentiment classification. arXiv preprint arXiv:2112.02690. Watanabe, H.; Tanaka, H.; Sakti, S.; and Nakamura, S. 2020. Synchronization between overt speech envelope and EEG oscillations during imagined speech. Neuroscience research, 153: 48–55.


