
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 분산표현
- csp알고리즘
- 잠재변수
- matlab
- csp 알고리즘
- neural representation learning
- 뇌과학
- brain-to-speech
- latent variable
- 책
- 기준음성
- AI윤리
- speech reconstruction
- 발화의도
- 블록체인
- imagined speech
- common spatial pattern
- BCI
- AI
- 뇌와 세계
- 신경과학
- HPC
- 미겔
- spoken speech
- gt voice
- neurotalk
- 헬싱키 선언
- Distributed Representation
- 표현학습
- 의료윤리
- Today
- Total
o0y0o
[논문 번역] Neural Speech Embeddings for Speech Synthesis Based on Deep Generative Networks 본문
[논문 번역] Neural Speech Embeddings for Speech Synthesis Based on Deep Generative Networks
_\oyo/_ 2024. 9. 25. 21:49■ Abstract
Brain-to-speech 기술은 인공지능, brain-computer interface, 음성 합성 등 다양한 학문 분야가 융합된 응용 기술을 나타냅니다.
Neural representation learning 기반의 발화 의도 해독과 음성 합성은 신경 활동을 인간의 언어적 의사소통 수단과 직접 연결하여, 의사소통의 자연스러움을 크게 향상시킬 수 있습니다.
Neural representation learning의 최신 발견과 음성 합성 기술의 발전을 바탕으로, brain signals을 음성으로 직접 변환하는 기술은 많은 가능성을 보여주고 있습니다.
특히, 신경망에 입력되는 처리된 입력 특징과 neural speech embeddings는 brain signals로부터 음성을 생성할 때, 딥 생성 모델의 전반적인 성능에 중요한 역할을 합니다.
이 논문에서는 brain signals로부터 음성 합성을 가능하게 하는 현재의 brain-to-speech 기술을 소개하며, 이는 궁극적으로 비언어적 의사소통에 혁신을 가져올 수 있습니다.
또한, 우리는 말하는 동안 신경생리학적 활성화를 기반으로 하는 신경 특징과 neural speech embeddings에 대한 종합적인 분석을 수행하며, 이는 음성 합성 작업에서 중요한 역할을 할 수 있습니다.
키워드
: brain-computer interface, deep neural networks, electroencephalogram, generative adversarial network, imagined speech, speech synthesis
■ INTRODUCTION
최근 BCI 분야에 대한 관심이 급증하고 있습니다. BCI는 인간이 brain signals를 사용하여 외부 장치와 상호작용하거나, 주변 환경을 제어할 수 있는 방법입니다. [1]
BCI 연구에서 사용되는 다양한 방법 중, electroenchphalography(EEG, 뇌전도)가 특히 주목할 가치가 있습니다. EEG는 전극을 두피에 부착하여 전기 활동을 기록하며, 전극을 이식하는 등의 invasive한 절차가 필요하지 않기에 brain signals를 활용하는 응용 프로그램에서 중요한 정보 source로 사용됩니다. [2,3]
EEG 기반 BCI는 motor functions 제어, communication, cognitive assessment 등 광범위한 응용 분야에서 활용되었습니다. [4, 5, 6]
non-invasive한 EEG recoding에서 신호 품질이 낮은 문제에도 불구하고, EEG가 제공하는 편리함과 실용적인 장점 덕분에 수많은 응용 프로그램 연구가 이루어졌습니다. [7]
Brain-to-speech (BTS)는 인간의 brain signals로부터 가청 음성을 생성하는 새롭고 직관적인 BCI 의사소통입니다. [8]
이는 현재의 domain adaptation과 speech synthesis 기술을 통해 비언어적 의사소통을 가능하게 합니다.
Neural patterns는 신경 특징을 인간 언어와 직접 연관시켜 음성 언어로 변환됩니다.
이전 연구에서는 domain adaptation 프레임워크가 neural features와 speech ground truth 간의 자연스러운 대응을 확립하였습니다. [8]
따라서 silently imagined speech의 brain signals로부터 가청 음성을 생성할 수 있었으며, 이는 brain signals을 통해 의사소통할 수 있는 가능성을 보여줍니다.
모델의 입력 embedding으로 사용되는 feature embedding과 전처리 과정이 BTS 성능에 중요한 역할을 하는 것으로 알려져있습니다.
이 논문에서는 brain signals을 사용하여 음성을 직접 합성하는 BTS 기술에 대한 광범위한 분석을 제공합니다.
우리는 이전의 BTS 연구 [8]에 대한 심층 분석을 통해 BTS 성능을 크게 향상시키는 데 기여할 수 있을 것입니다.
이러한 발전은 비언어적 의사소통의 새로운 시대를 열어, 우리가 외부 세계와 상호작용하는 방식을 변화시킬 수 있습니다.
또한, 우리는 말하는 과정에서 신경의 특성과 신경생리학적 과정에 대한 종합적인 검토를 진행할 것입니다.
이 연구는 발화 메커니즘을 명확히 하고, 음성 합성 분야에서 중요한 발전을 가져올 것입니다.
이러한 신경 특징에 대한 이해는 인간 의사소통에 대한 이해를 높이고, BTS 기술의 발전에 중요한 통찰을 제공할 것입니다.
■ MATERIALS AND METHODS
▷ Dataset
이 연구에서는 6명의 참가자들이 speaking tasks에 참여할 때의 EEG 신호와 speaking recoding을 사용했습니다.
64채널 전극 배열을 참가자들의 두피에 배치하여 EEG 데이터를 기록했으며, 마이크를 사용해 음성을 녹음했습니다.
마이크는 EEG 신호와 동기화되었습니다.
참가자들은 화면에 표시된 지시에 따라 말하도록 지시받았습니다. 이 실험 설정은 [9]의 이전 연구와 일관되었습니다.
참가자들은 화면에 표시된 지시에 따라 imagined speech와 spoken speech를 수행하도록 지시받았습니다.
Spoken speech 세션에서는 각 참가자의 음성을 마이크로 녹음했으며, spoken speech의 EEG와 동기화되었습니다.
▷ Preprocessing
EEG 신호는 각 trial마다 2초 간격으로 분할되었습니다.
EEG 데이터는 filtering 과정을 거쳤으며, 여기에는 Lachaux et al. [10]에 따르면 발화 관련 정보와 관련이 있는 것으로 잘 알려진 high-gamma 주파수 범위(30-120 Hz)의 5차 Butterworth bandpass filter가 포함되었습니다.
또한, 60 Hz 및 그 고조파인 120 Hz에서 발생하는 전원선 노이즈를 줄이기 위해 notch filter가 적용되었습니다.
Spoken speech 동안의 눈과 근육 활동에서 발생하는 아티팩트를 제거하기 위해 electrooculography와 electromyography를 참조한 독립 성분 분석(ICA)이 사용되었습니다.
Baseline correction은 각 trial 시작 전 500 ms의 평균 신호를 빼서 수행되었습니다.
모든 전처리 과정은 Python과 MATLAB, BBCI Toolbox [11], EEGLAB [12]를 사용해 실행되었습니다.
음성 데이터의 경우, resampling을 수행하여 음성 신호를 22,050 Hz의 샘플링 레이트로 조정했고, noisereduce 라이브러리 [13]를 사용해 노이즈를 줄였습니다.
▷ Feature Embeddings
발화 관련 brain signals에서는 공간적, 시간적, 주파수 정보가 중요한 요소로 인식되며, vector 기반 brain embedding features는 이 신호 안에 포함된 맥락적 의미를 전달할 수 있습니다.
Embedding vector는 common spatial pattern (CSP)을 사용해 공간 패턴을 최적화하고, log-variance를 사용해 시간적 진동 패턴을 추출하는 방식으로 생성되었습니다.
CSP는 공분산 행렬을 이용해 가장 효과적인 공간 필터를 찾는 기술로, 발화와 관련된 brain signals를 해독하는 데 중요한 역할을 합니다.
Spoken EEG와 imagined EEG 간의 데이터 분포 차이를 최소화하기 위해, 두 EEG 신호에서 CSP 필터를 공유했습니다 [8].
특히, CSP 필터는 일부 노이즈가 포함될 수 있는 spoken EEG 대신, 순수한 brain signals만 포함한 imagined EEG로 훈련되었습니다.
이러한 CSP 필터를 공유함으로써 spoken EEG 도메인을 imagined EEG의 서브스페이스에 효과적으로 적응시켰습니다.
▷ Spatio-temporal Analysis
Spoken speech와 imagined speech를 수행할 때의 brain activation을 비교하기 위해 시간적, 공간적, 주파수 특징을 분석했습니다.
공간적 특징에서는 중앙엽의 desynchronization과 측두엽의 synchronization이 두드러졌습니다.
주파수 특징에서는 90 Hz 이상의 high-frequency 범위에서 dominant한 synchronization이 나타났습니다.
Imagined speech와 spoken speech 모두 주로 high-frequency 범위에서 500-1,250 ms 동안 dominant한 desynchronization 패턴을 보여, BTS 프레임워크가 두 가지 다른 발화 brain signal 도메인을 서로 적응시키려 한다는 것을 뒷받침합니다 [8].
■ RESULTS AND DISCUSSION
▷ Feature Embeddings

Fig. 1은 spoken speech와 imagined speech 동안의 활성화 시간 지점을 보여주며, 상당히 유사한 결과를 나타냅니다.
이 결과는 imagined speech의 feature embedding이 spoken speech의 측면을 따르고 있음을 보여주며, 이는 인코딩 아키텍처가 spoken speech EEG뿐만 아니라 imagined speech EEG에서도 관련 시간 지점을 포착할 수 있음을 시사합니다.
CSP 패턴과 log-variance가 spoken 또는 imagined voice의 여러 특징을 나타낼 수 있음을 의미하므로, 우리는 이러한 embedding vectors를 모델의 입력으로 사용하여 사용자의 목소리를 재구성했습니다.
▷ Embedding Vector Distributions
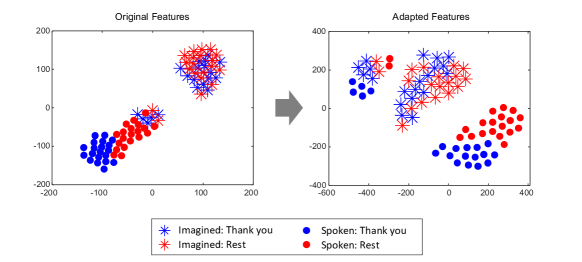
Spoken features와 imagined features의 분포는 CSP 패턴을 공유하기 전에는 서로 분리된 위치에 있었으나, 공유된 CSP 패턴을 사용하여 적응된 features는 상대적으로 더 가까운 latent space에 배치되었으며, 이는 classifier를 공유하거나 domain shift가 좁은 범위 내에서 수행될 수 있음을 의미합니다 (Fig. 2).
우리의 도메인이 주로 이미지나 음성 도메인에 비해 매우 불분명한 brain signal인 만큼, 각 클래스의 클러스터는 상대적으로 soft margins를 보여줍니다.
▷ Spatio-spectral Features

발화 중 brain activity의 차이를 탐구하기 위해, 공간적 및 주파수적 특징을 분석하였습니다 (Fig. 3).
공간적 특징에 대한 분석 결과, 중앙엽에서의 주목할 만한 synchronization과 측두엽에서의 desynchronization이 확인되었으며, 이는 Lee et al. [14]의 연구 결과와 일치합니다.
주파수 특징에서는 30-120 Hz의 high-gamma 주파수 범위에서 강한 synchronization을 발견하였으며, 이는 이전 연구 [15, 16, 17]에서 입증된 바 있습니다.
이 high-gamma 주파수 대역은 추가 분석을 위해 선택되었습니다.
또한, 각 텍스트는 고유한 brain activation 패턴을 보였으며, 이는 발화의 다양한 측면이 별개의 neural networks를 작동시킬 수 있음을 시사합니다.
이러한 뇌 활성화 패턴은 발화 생성에 관련된 운동 과정의 반영일 수 있습니다.
▷ Limitations and Future Works
우리 연구는 13개의 단어로 구성된 데이터셋으로 제한되었습니다.
우리는 이 단어들에 포함된 모든 phoneme을 통합하여 새로운 단어를 생성할 수 있도록 모델을 준비하려고 노력했지만, 결과는 기대에 미치지 못했습니다.
앞으로의 목표는 더 광범위한 phoneme을 포함한 문장을 다루는 데이터셋을 사용하여 연구를 확장하는 것입니다.
최근 functional magnetic resonance imaging (fMRI)를 사용해 의미적 사고를 해독하는 연구와 같은 혁신은 brain signals가 언어 장벽을 넘어 의사소통을 가능하게 할 수 있음을 보여주었고, neural signals의 직접적인 번역 가능성을 제시했습니다.
우리는 확장된 데이터셋이 speech 과정에 관련된 neural features를 더 정확하게 조사할 수 있게 해줄 것으로 기대합니다 [18, 19, 20].
또한, 우리는 우리의 제안된 방법론을 invasive한 방법에 적용하려고 합니다.
Speech BCI는 환자 맞춤형 적용과 일반적 응용 모두에서 중요한 역할을 하기 때문입니다.
환자들에게는 invasive한 방법이 acoustic 정보와 motor 정보를 포함하는 발음 기관의 움직임을 해독하는 데 초점을 맞추고 있으며, 이는 발화 장애를 겪고 있는 사람들에게 의사소통 도구로 활용될 수 있습니다 [2].
■ CONCLUSION
BCI 기술은 종종 개인의 사적인 마음을 읽는 것과 같은 잠재적인 우려를 동반합니다.
하지만 현재의 기술은 사용자가 EEG cap이나 brain signal 데이터를 수집하는 장치를 착용할 때에만 의도된 이미지를 해독할 수 있습니다.
미래에는 brain reading을 통한 사생활 침해 등 부정적인 사회적 영향이 발생할 수 있지만, brain signal 데이터는 원격으로 수집할 수 없기 때문에(음성, 비디오, 라디오파와는 달리), EEG cap을 벗거나 장치를 끄는 방식으로 이러한 잠재적인 위협에 대처할 수 있습니다.
BTS 프레임워크는 몇 가지 소리만 낼 수 있는 장애인이나, 향후 발화 능력을 상실할 수 있는 환자들(예: amyotrophic lateral sclerosis 환자)에게 도움이 될 수 있습니다.
우리는 BTS 기술이 많은 사람들의 삶을 개선하는 데 긍정적으로 사용되기를 바랍니다.
■ References
- [1]U. Chaudhary, N. Birbaumer, and A. Ramos-Murguialday, “Brain–computer interfaces for communication and rehabilitation,” Nat. ReviewsNeurology, vol. 12, no. 9, pp. 513–525, 2016.
- [2]K.-T. Kim, C. Guan, and S.-W. Lee, “A subject-transfer framework based on single-trial EMG analysis using convolutional neural networks,” IEEE Trans. Neural Syst. Rehabil.Eng., vol. 28, no. 1, pp. 94–103, 2019.
- [3]K.-H. Thung et al., “Conversion and time-to-conversion predictions of mild cognitive impairment using low-rank affinity pursuit denoising and matrix completion,” Med. ImageAnal., vol. 45, pp. 68–82, 2018.
- [4]S. Kim, Y.-E. Lee, S.-H. Lee, and S.-W. Lee, “Diff-E: Diffusion-based learning for decoding imagined speech EEG,” in Interspeech.
- [5]R. Mane et al., “FBCNet: A multi-view convolutional neural network for brain-computer interface,” arXiv preprintarXiv:2104.01233, 2021.
- [6]M. Lee, C.-B. Song, G.-H. Shin, and S.-W. Lee, “Possible effect of binaural beat combined with autonomous sensory meridian response for inducing sleep,” Front. Hum.Neurosci., vol. 13, pp. 425–440, 2019.
- [7]Y.-E. Lee, N.-S. Kwak, and S.-W. Lee, “A real-time movement artifact removal method for ambulatory brain-computer interfaces,” IEEE Trans. on Neural Systems RehabilitationEngineering, vol. 28, no. 12, pp. 2660–2670, 2020.
- [8]Y.-E. Lee, S.-H. Lee, S.-H. Kim, and S.-W. Lee, “Towards voice reconstruction from EEG during imagined speech,” in AAAI Conf. Artif. Intell.(AAAI).
- [9]S.-H. Lee, M. Lee, and S.-W. Lee, “Neural decoding of imagined speech and visual imagery as intuitive paradigms for BCI communication,” IEEE Trans. Neural Syst. Rehabil.Eng., vol. 28, no. 12, pp. 2647–2659, 2020.
- [10]J.-P. Lachaux, N. Axmacher, F. Mormann, E. Halgren, and N. E. Crone, “High-frequency neural activity and human cognition: Past, present and possible future of intracranial EEG research,” Prog. Neurobiology, vol. 98, no. 3, pp. 279–301, 2012.
- [11]R. Krepki, B. Blankertz, G. Curio, and K.-R. Müller, “The Berlin brain-computer interface (BBCI)–towards a new communication channel for online control in gaming applications,” Multimed. Tools Applications, vol. 33, no. 1, pp. 73–90, Feb. 2007.
- [12]A. Delorme and S. Makeig, “EEGLAB: An open source toolbox for analysis of single-trial EEG dynamics including independent component analysis,” J. NeuroscienceMethods, vol. 134, no. 1, pp. 9–21, 2004.
- [13]T. Sainburg, M. Thielk, and T. Q. Gentner, “Finding, visualizing, and quantifying latent structure across diverse animal vocal repertoires,” PLoS ComputationalBiology, vol. 16, no. 10, p. e1008228, 2020.
- [14]S.-B. Lee et al., “Comparative analysis of features extracted from EEG spatial, spectral and temporal domains for binary and multiclass motor imagery classification,” Inf.Sci., vol. 502, pp. 190–200, 2019.
- [15]S.-H. Lee, M. Lee, J.-H. Jeong, and S.-W. Lee, “Towards an EEG-based intuitive BCI communication system using imagined speech and visual imagery,” in Conf. Proc. IEEE Int. Conf. Syst. Man Cybern.(SMC), pp. 4409–4414.
- [16]G. K. Anumanchipalli, J. Chartier, and E. F. Chang, “Speech synthesis from neural decoding of spoken sentences,” Nature, vol. 568, no. 7753, pp. 493–498, 2019.
- [17]J. Kim et al., “Abstract representations of associated emotions in the human brain,” J.Neurosci., vol. 35, no. 14, pp. 5655–5663, 2015.
- [18]J.-S. Bang, M.-H. Lee, S. Fazil, C. Guan, and S.-W. Lee, “Spatio–spectral feature representation for motor imagery classification using convolutional neural networks,” IEEE Trans. Neural Netw. Learn.Syst., vol. 33, no. 7, pp. 3038–3049, 2021.
- [19]M. Angrick et al., “Real-time synthesis of imagined speech processes from minimally invasive recordings of neural activity,” Commun.Biol., vol. 4, no. 1, pp. 1–10, 2021.
- [20]H.-I. Suk, S. Fazli, J. Mehnert, K.-R. Müller, and S.-W. Lee, “Predicting BCI subject performance using probabilistic spatio-temporal filters,” PLoSOne, vol. 9, no. 2, p. e87056, 2014.


